Using newline-separated JSON to efficiently process large amounts of data with Node.js
February 21, 2020
We are all used to using JSON as a data format for communication between services. To process data from a JSON string, a computer needs to parse it as a whole. Parsing can get problematic in cases when a JSON contains a massive amount of data. Increasing the heap memory is just a temporary solution and can only get you so far. What we want to achieve is having many small interchangeable processes running in a cluster. The processes need to be able to serve many concurrent requests without the risk of one request starving the process of memory needed to serve the others. We need to try achieving this goal regardless of the number of requests and their size.
One such use case that got me thinking about all of this is when we want to periodically send a vast number of requests to a service in a short time. Let's imagine that we had a client app which would crawl websites to extract usernames, emails and profile pictures from the user profiles.
On our server-side, we would need an endpoint that could receive each profile, upload the profile picture and save the user data to a database. Unfortunately, there is a limitation in some runtimes (e.g. browsers) which gets in our way. For example, in Chrome, if we needed to make a thousand requests immediately, we would be able to make only six at a time.
The browser queues all the other requests and executes them one by one as the first six are being resolved. That is due to a self-imposed limitation in most HTTP/1.0 and HTTP/1.1 clients which limits the number of HTTP requests that can be issued concurrently. In our example, this limitation increases the perceived latency of our service by a factor of 1000/6.
To get around the six (or so) connection limit, we can group the requests and send them in one big batch. Instead of sending one profile at a time, we would send a JSON array containing 1000 profiles.
# Approach No. 1: Naive json parsing
Here is an example express app which does just that. I 've decided to go with express as it is the most common way people would solve this. Of course, express is not required; you can find the bare node implementation in this gist.
The app listens on a port, and when a POST request is received completely, the body-parser middleware parses it as JSON and then stores the data user-by-user to the database, all within a single transaction.
To save a user profile, we need to decode the base64-encoded image and then store it to a uniquely named file on the disk (we could've also uploaded it somewhere) and then save the username, email and image location to the database.
For test purposes let's run our database.
docker run --rm --name jsonl-demo-postgres -e POSTGRES_PASSWORD=postgres -d -p 5432:5432 postgresAnd create our database table called users:
docker exec -it jsonl-demo-postgres psql -d postgres://postgres:postgres@localhost:5432/postgres -c 'create table users (user_id serial PRIMARY KEY, name varchar(255), email varchar(255));'We can make a request using:
curl -X POST -H "Content-Type: application/json" --data-binary @1000-users.json http://localhost:8000user.json's' size is 120 KB.
Let's start our app and observe the memory usage using appmetrics dashboard.
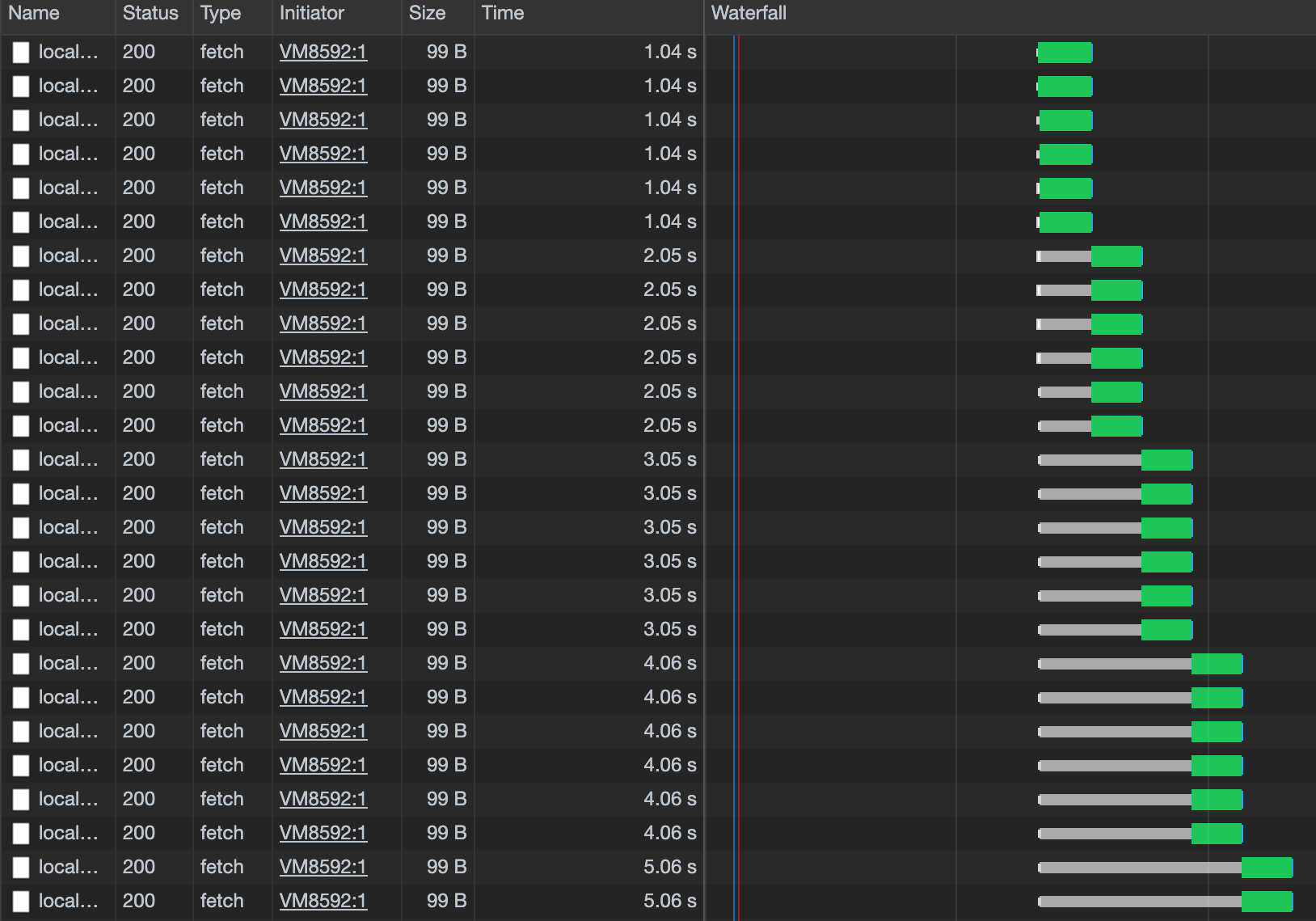
DB_URI=postgres://postgres:postgres@localhost:5432/postgres node --require appmetrics-dash/monitor naive-express.jsWe start with sending 1000 users in our request body. The size of the body is 117 MB.
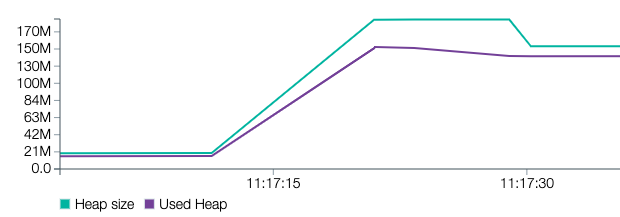
Let's make it more interesting and add 5000 users to our request body. The size of the body is now 584 MB.
The memory consumption equals the overall size of the requests that are being made in a given moment. It is not unlikely that at a certain point all the messages being kept in memory at the same time will exceed the (default) max v8 heap size (1400MB ) limit which will terminate our process.
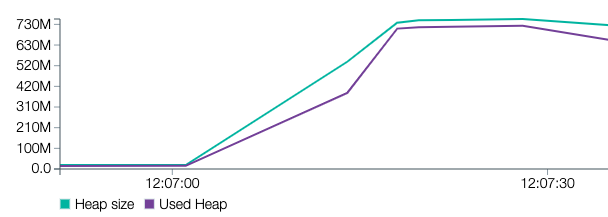
What would happen if we had multiple clients sending such big payloads or if the payload is even bigger? Here is what we get for 10000 users (1.1 GB):
# Approach No. 2: Using streams
For the arrays of objects of the same type, there is a way around this problem. Instead of representing the data as a JSON array, we can represent it as a collection of newline-separated elements. This format is called JSON Lines.
Instead of sending:
[{"user": "vladimir", email: "someone@gmail.com", image: "some long base64 string"},{"user": "george", email: "george@vandeley.com", image: "some other base64 string"}]{"user": "vladimir", email: "someone@gmail.com", image: "some long base64 string"}\n{"user": "george", email: "george@vandeley.com", image: "some other base64 string"}Line-separated data elements can be read, parsed and processed as they are being read from the socket, without waiting for the rest of the elements to be received. This approach is much more memory efficient as only the elements which are processed at a given time are kept in memory. The moment the element is processed, it can be passed on to the next process such as the next service, a database, stdout or be presented to the user. To process this kind of data in Node.js, we need to use its stream API. Streams are not used that much as more practical higher-level abstractions are available and are sufficient for most use cases.
Let's create a server which pipes the HTTP request stream to a transformer and then outputs the data. We can also do this with express as the express request is just a regular Node.js request (with some other express.js utilities bolted on).
The most crucial part for this to work is the ChunksToLine Transformer.
There are a couple of ways to implement a Transformer, but I found extending the Transformer class to be the most convenient. Our Transformer receives Buffer chunks from the request stream, and to read from them we need to convert them to strings. Converting to chunks to strings is a common use-case, so Node.js has the StringDecoder built-in.
Next, we need to implement the Transformer's _transform method. Transformer collects all the chunks in the buffer, and if there are one or more complete JSONs received it passes them on, while keeping the rest to concatenate with the next chunk.
Of course, this implementation is written for educational purposes and as such is not well tested and suitable for use in production. There are some better JSON lines transformer implementations out there which are production-ready such as split and split2. They can be used as a drop-in replacement as they are both stream Transformers.
Let's repeat the previous tests with the new implementation. Of course, in this case, instead of sending a JSON array, we send a JSON lines payload of the same size.
curl -X POST -H "Content-Type: application/json" --data-binary @1000-users.jsonl http://localhost:8000
With 1000 users (117 MB)
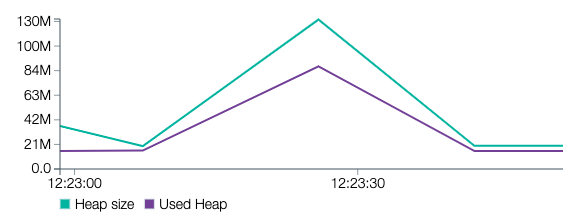
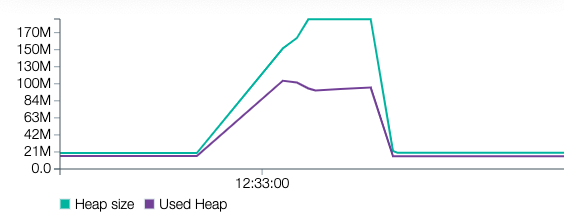
With 5000 users (584 MB)
With 10000 users (1.1 GB)
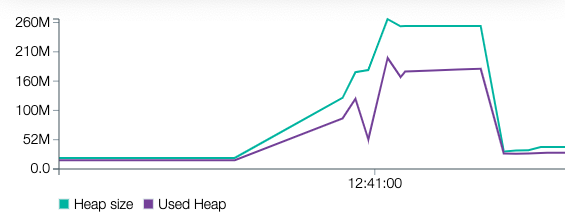
We can see that the increase in memory size is somewhat correlated with the size of the payload but is much lower than with the previous implementation. By splitting our payload in independent chunks, we can process it much faster and with less memory consumption. Stream processing that kind of payload makes our service more reliable and makes running it cheaper.